RetroSeach: a stupid retro computing project
Context
Between one gig and the other, I decided to get back to one of my good old passions, you know, the ones that make you fun at parties: retro computing.
So, overexcited by the wait of solder stations and replacement caps for my newly acquired Macintosh Classic and Macintosh LC, I figured I could cool my heels by giving this website an old look (the one you’re seeing right now!). It wasn’t enough.
Every time I fix something, I really try to use it as much as I can before getting bored and giving up, and that’s what scared me when the graphics revamp of the blog was done and I went back to waiting for FedEx. During mindless Internet browsing, I acquired as much abandonware and resources for my soon to be fixed computers and looked into more and more projects the retro computing people have been working on. One of them was FrogFind, which refused to work while I was giving it a try. Sad. :(
The Project
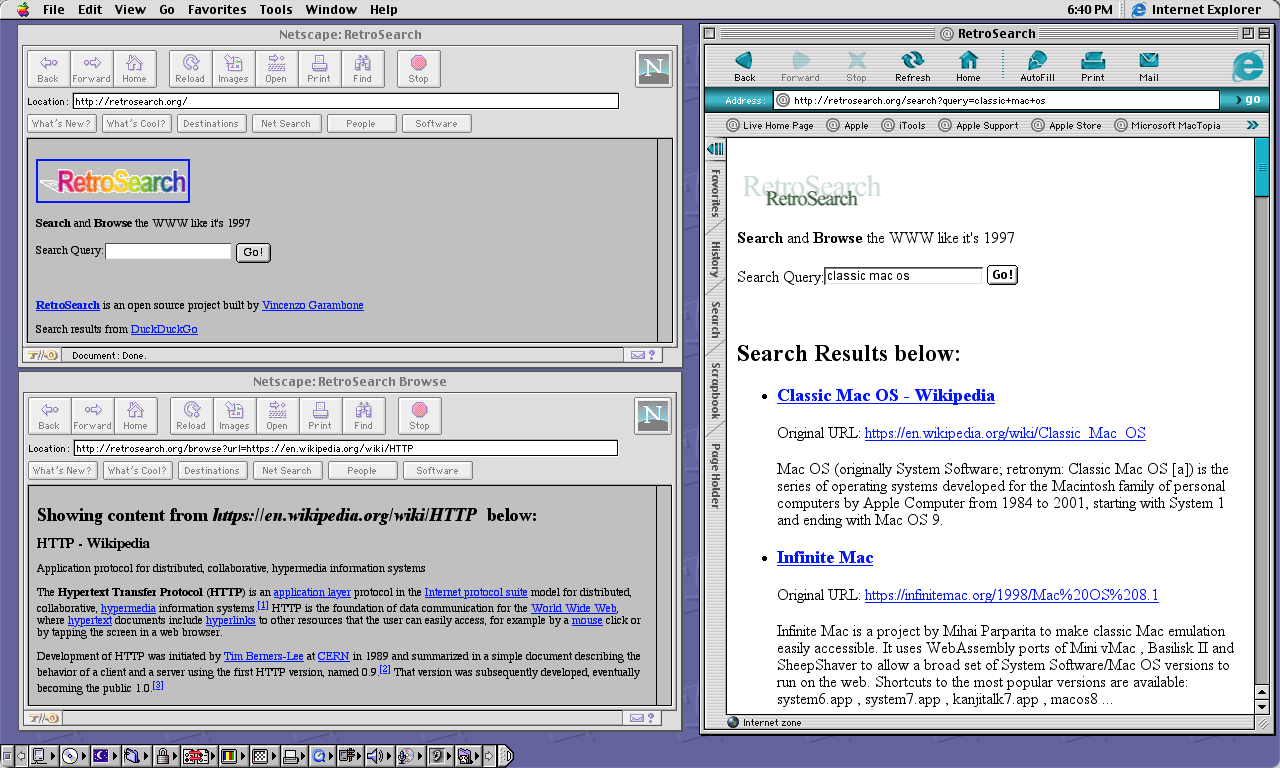
I found the concept of using a scraper for DuckDuckGo and an implementation of Mozilla’s Readability API interesting for a quick project, and, since I just finished giving a couple of lectures about Spring, that was the perfect opportunity to develop something I could use with my old computers to surf the Internet using browsers like Netscape 2.0 or Mosaic.
Long story short: parse long and complex web pages and return them to the poor old computer’s browser with three main features:
- using simple HTML, with tags from the HTML 2.0 standard or earlier
- ISO-8859-1 encoding
- no images (except for a 3KB logo, of course)
So, after a couple of days of fun, here’s RetroSearch, It is available at retrosearch.org.
If you want to contribute, check out the code, or have any suggestions, you can take a look at the GitHub repo.
And… It features not one, not two, but three horrible WordArt-style logos! Such a gem!